多机集群上部署 Slurm 有没有什么简单快捷的方法呢?
前言
前段时间为了能让运行的 CONQUEST 任务在后台运行、并尽可能地进行资源调控,特别采用了 Slurm 作业管理系统。Slurm 单节点的部署配置还是比较简单的,直接运行本人构建好的镜像就可以了。随着对 Slurm 的深入了解,笔者发现 Slurm 在集群部署上比其他作业管理系统更加简单方便,因此有了在多机集群上部署一个 Slurm 集群的想法。经过调查发现以下两种通用的部署 Slurm 集群的方案:
- 第一种是:在物理机或虚拟机上采用 Slurm + Database 的方式部署,
- 第二种是:在 Docker 集群上使用 Docker 部署。
考虑到应用环境的部署应尽可能与物理机环境隔离开,所以个人偏向于采用 Docker 的方式部署 Slurm 集群。再者说,无论是部署、管理上的便捷性,还是未来的可扩展性,这种方式都是更有优势的。在网上经过一番搜索后,本人发现了一个类似的“使用 Docker 部署 Slurm 集群”的开源项目 SciDAS/slurm-in-docker。总的来说,这个项目在设计上的确是很完整的,设计的架构图也非常好,但是在对这个项目的学习和实践过程中也发现一个问题。不知道是不是经过了版本迭代的缘故,有一些代码的目录组织有些出入,在构建基础镜像的时候就失败了。加之,这个项目采用了数据库,而且只适用于单机上部署 Slurm 集群,和本人的诉求有些不一致。所以也排除了这种方法。
本人目前的条件和需求如下:
- 拥有若干台服务器的非 root 权限用户账号和 Docker 运行权限;
- 服务器之间共用了同一个 NAS 服务器;
- 想要在这些服务器上搭建一个可用的高性能 Slurm 集群。
根据往常的经验,觉得可能还是需要先 Docker 集群化,然后在 Docker 集群上运行 Slurm 集群。而目前比较熟知的流行的 Docker 集群化方法主要有 swarm,kubernetes 以及 rancher 等,但是这些基本上都需要 root 权限,并需要安装某些软件在物理机系统上,这与现有的条件和想法还是有点冲突。所以产生了一个大胆的想法——如果没有 Docker 集群,能不能部署可用的高性能 Slurm 集群呢?这个想法其实在上面提到的开源项目的架构图(下图)中就找到了答案。如图所示,对于 Slurm 集群来说最重要的其实是 6817 和 6818 两个端口的通信。图中的数据库的目的是为了保证 Slurm 节点的用户名一致,事实上可以想到别的办法来替代它。所以,即使把数据库去掉,也不建立集群节点之间的相互无密码登录,只要保证 Slurm 节点的这两个端口能够互相访问到,就可以成功部署 Slurm 集群。
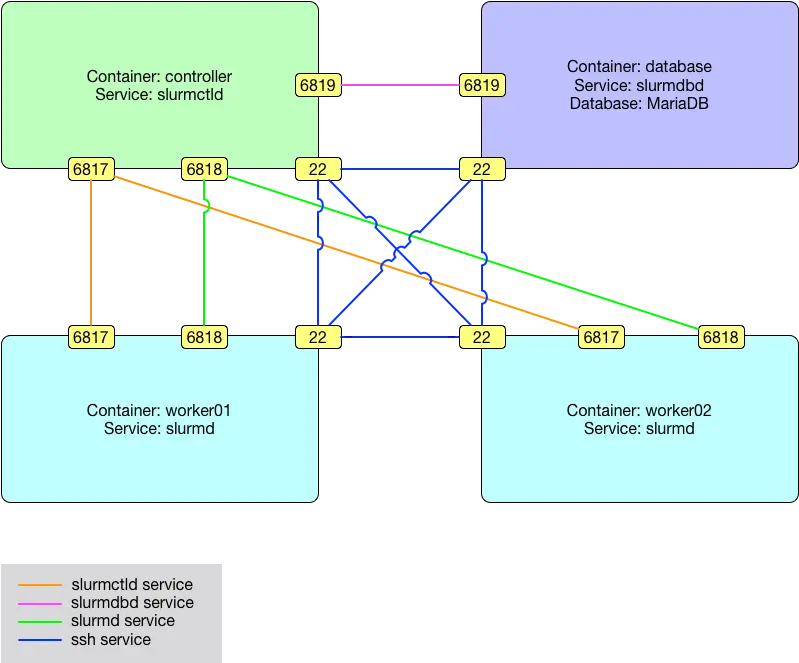 (上图引用自 https://github.com/SciDAS/slurm-in-docker )
(上图引用自 https://github.com/SciDAS/slurm-in-docker )
安装配置
Slurm 集群的节点之间通过 6817 和 6818 两个端口进行通信,其基础的配置就是 munge key 和 slurm.conf 两个文件一致,相互之间互信。如果不同服务器上采用相同的 Docker 镜像的话,那么 munge key 肯定是一致的。而 slurm.conf 文件的一致性可以在启动时用挂载的方式使用同样的文件来保证。当然,这里也需要集群节点之间能够互相“认识”对方,即可以通过主机名来知道对方的 ip,并通过开放的端口进行通信。为此,使用同样的、有完整 ip 对应的 hosts 文件以及固定的 hostname 也是有必要的。
事实上,这里有两点我们还需要注意一下:
- 当 Slurm 集群中的节点互相之间都可以通过给定的两个端口进行通信之后,任何一个节点都可以作为任务管理节点。这也就是说,节点之间是等价的,不存在绝对的管理节点,这也从侧面提高了集群的可靠性。
- 服务器的操作系统和 Docker 版本对这个方案没有任何影响,只要 Docker 镜像完全相同即可。
因为本人的主要目的还是要在 Slurm 集群上运行 CONQUEST,所以就以 CONQUEST 的 slurm-ssh 镜像为例。
环境描述
- 有三台已安装 Docker 的 Ubuntu 服务器
- 已安装 docker-compose 工具
部署配置文件
将 slurm.conf 和 Hostname 文件放置在 NAS 共享目录 /data/slurm/,文件内容如下:
# slurm.conf file generated by configurator easy.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ControlMachine=worker01
#ControlAddr=
#
#MailProg=/bin/mail
MpiDefault=none
#MpiParams=ports=#-#
ProctrackType=proctrack/pgid
ReturnToService=1
SlurmctldPidFile=/var/run/slurm-llnl/slurmctld.pid
SlurmctldPort=6817
SlurmdPidFile=/var/run/slurm-llnl/slurmd.pid
SlurmdPort=6818
SlurmdSpoolDir=/var/spool/slurmd
SlurmUser=slurm
#SlurmdUser=root
StateSaveLocation=/var/spool/slurm-llnl
SwitchType=switch/none
TaskPlugin=task/none
#
#
# TIMERS
#KillWait=30
#MinJobAge=300
#SlurmctldTimeout=120
#SlurmdTimeout=300
#
#
# SCHEDULING
FastSchedule=1
#SchedulerType=sched/backfill
#SelectType=select/linear
SelectType=select/cons_res
SelectTypeParameters=CR_CPU
#
#
# LOGGING AND ACCOUNTING
AccountingStorageType=accounting_storage/none
ClusterName=workq
#JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/none
#SlurmctldDebug=3
#SlurmctldLogFile=
#SlurmdDebug=3
#SlurmdLogFile=
#
#
# COMPUTE NODES
NodeName=worker01 CPUs=128 State=UNKNOWN
NodeName=worker02 CPUs=128 State=UNKNOWN
NodeName=worker03 CPUs=128 State=UNKNOWN
PartitionName=cpu Nodes=ALL Default=YES MaxTime=INFINITE State=UP
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.100.11 worker01
192.168.100.12 worker02
192.168.100.13 worker03
启动 Docker 实例
为了便于启动和管理 Docker 实例,这里建议采用 docker-compose 的方式。以下为 docker-compose.yml 文件内容:
version: '3.9'
services:
worker01:
image: zhonger/conquest:slurm-ssh
container_name: worker01
stdin_open: true
tty: true
volumes:
- /data/slurm/slurm.conf:/etc/slurm-llnl/slurm.conf
- /data/slurm/hosts:/etc/hosts
- /data/cq:/home/ubuntu/cq
ports:
- 6817:6817
- 6818:6818
environment:
- GITHUB_NAME=zhonger
restart: always
hostname: worker01
networks:
extnetwork:
ipv4_address: 192.168.16.2
networks:
extnetwork:
ipam:
config:
- subnet: 192.168.16.0/24
gateway: 192.168.16.1
这里为了支持 ssh 登录特意添加了 networks 节来规范容器实例 ip,非管理节点建议去掉这一节。另外,每个主机上的 container_name 和 hostname 都应该分别对应修改为 worker02 和 worker03。
使用 docker-compose up -d 命令在三台主机上启动容器实例(此处主机启动实例先后顺序没有区别,可以随意调整)。在最后启动的实例所在宿主机上使用 docker logs {container_name} 命令可以看到所有 Slurm 集群节点都处于 idle (空闲)状态。至此,一个可用的 Slurm 高性能集群就搭建成功了,是不是觉得有点简单哈?
问题解决
问题描述:偶然发现 Slurm 集群中某些节点状态变成了 Unknown 怎么办?
解决办法:在该节点的容器内使用 sudo service slurmctld restart 尝试重启 slurmctld 服务。一般情况下这样做是有效的,但也有不好使的时候,那么就可以在宿主机上 docker-compose.yml 所在目录使用 docker-compose down && docker-compose up -d 重建该节点。注意,由于配置文件和主要代码文件都是用的 NAS,这里的容器销毁和重建是不会有任何影响的。
问题描述:集群的管理节点成功启动但是一直处于 Unknown 状态怎么办?
解决方法:这个问题和上一个问题描述上听着有点差不多,但是有所区分。如果是管理节点处于 Unknown 状态,并且经过上一问题解决方法还是不在线,那么就需要将管理节点调整到其他节点。调整管理节点就是将 slurm.conf 文件中 ControlMachine 字段修改一下就可以,修改之后对所有节点进行重建(不是重启容器实例哦)。
问题描述:如果没有共用 NAS 怎么办?
解决方法:在没有共用 NAS 的情况下,想要 Slurm 集群的节点共用同样的配置和代码目录可以通过“在管理节点物理机上搭建 NFS 服务器”的方式来解决。关于 NFS 服务器的搭建和容器中挂载 NFS 文件系统的有关教程可以在网络上搜索到,这里就不再赘述了。
问题描述:集群中的某个节点在集群中的状态为 Down 怎么办?
解决方法:这种情况下,只需要在 Down 状态的节点中运行 sudo scontrol show node 命令确认一下是否因为物理机重启而造成节点状态发生改变。如果是 Reason=Node unexpectedly rebooted,就是这个原因导致的。可以采用 sudo scontrol update NodeName=worker01 State=IDLE 命令将该节点的状态重新设为空闲可用。
参考资料
版权声明: 如无特别声明,本文版权归 仲儿的自留地 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 Docker 快速部署 Slurm 集群 》
本文链接:https://lisz.me/tech/docker/docker-slurm-cluster.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

Developer & Maintainer

